Tails You Win, One Tail You Lose
I presented the math for this at the #cosyne19 diversity lunch today.
— Megan Carey (@meganinlisbon) March 2, 2019
Success rates for first authors with known gender:
Female: 83/264 accepted = 31.4%
Male: 255/677 accepted = 37.7%
37.7/31.4 = a 20% higher success rate for men https://t.co/u2sF5WHHmy
Controversy over hypothesis testing methodology encountered in the wild a second time! At this year’s Computational and Systems Neuroscience conference, CoSyNE 2019, there was disagreement over whether the acceptance rates indicated bias against women authors. As it turns out, part of the disupute turned over which statistical test to run!
Controversial Data
CoSyNe is an annual conference where COmputational and SYstems NEuroscientists to get together. As a conference in the intersection of two male-dominated fields, concerns about gender bias abound. Further, the conference uses single-blind review, i.e. reviewers but not submitters are anonymous, which could be expected to increase bias against women, though effects might be small.
During the welcome talk, the slide below was posted (thanks to Twitter user @neuroecology for sharing their image of the slide; they have a nice write-up data mining other CoSyNe author data) to support the claim that bias was “not too bad”, since the ratio of male first authors to female first authors was about the same between submitted and accepted posters.
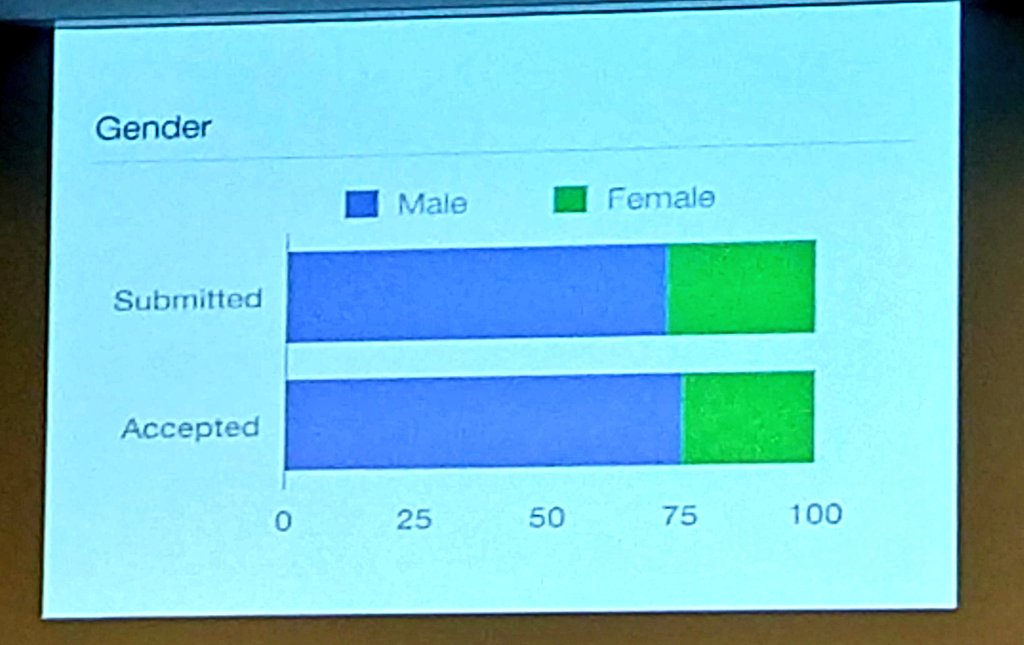
However, this method of viewing the data has some problems: the real metric for bias isn’t the final gender composition of the conference, it’s the difference in acceptance rate across genders. A subtle effect there would be hard to see in data plotted as above.
And so Twitter user @meganinlisbon got hold of the raw data and computed the acceptance rates and their ratio in the following tweet:
I presented the math for this at the #cosyne19 diversity lunch today.
— Megan Carey (@meganinlisbon) March 2, 2019
Success rates for first authors with known gender:
Female: 83/264 accepted = 31.4%
Male: 255/677 accepted = 37.7%
37.7/31.4 = a 20% higher success rate for men https://t.co/u2sF5WHHmy
Phrased as “20% higher for men”, the gender bias seems staggeringly high!
It seems like it’s time for statistics to come and give us a definitive answer. Surely math can clear everything up!
Controversial Statistics
Shortly afterwards, several other Twitter users, including @mjaztwit and @alexpiet attempted to apply null hypothesis significance testing to determine whether the observed gender bias was likely to be observed in the case that there was, in fact, no bias. Such a result is called significant, and the degree of evidence for significance is quantified by a value \(p\). For historical reasons, a value of \(0.05\) is taken as a threshold for a binary choice about significance.
And they got different answers! One found that the observation was not significant, with \(p \approx 0.07\), while the other found the the observation was significant, with \(p \approx 0.03\). What gives?
There were some slight differences in low-level, quantitative approach: one was parametric, the other non-parametric. But they weren’t big enough to change the \(p\) value. The biggest difference was a choice made at a very high level: namely, are we testing whether there was any gender bias in CoSyNe acceptance, or are we testing whether there was more specifically gender bias against women.
The former is called a two-tailed test and is more standard. Especially in sciences like biology and psychology, we don’t know enough about our data to completely discount the possibility that there’s an effect opposite to what we might expect.
Because we consider extreme events “in both directions”, the typical effect of switching from a two to a one-tailed test is to cut the \(p\)-value in half. And indeed, we \(0.03\) is approximately half of \(0.07\).
But is it reasonable to run a two-tailed test for this question? The claims and concerns of most of the individuals concerned about bias was framed specifically in terms of female-identifying authors (to my recollection, choices for gender identification were male, female, and prefer not to answer, making it impossible to talk about non-binary authors with this data). And given the other evidence for misogynist bias in this field (the undeniably lower rate of female submissions, the near-absence of female PIs, the still-greater sparsity of women among top PIs) it would be a surprising result indeed if there were bias that favored women in just this one aspect. Suprising enough that only very strong evidence would be sufficient, which is approximately what a two-tailed test does.
Even putting this question aside, is putting this much stock in a single number like the \(p\) value sensible? After all, the \(p\) value is calculated from our data, and it can fluctuate from sample to sample. If just two more female-led projects had been accepted or rejected, the two tests would agree on which side of \(0.05\) the \(p\) value lay!
Indeed, the CoSyNe review process includes a specific mechanism for randomness, namely that papers on the margin of acceptance due to a scoring criterion have their acceptance or rejection determined by the output of a random number generator.
And the effect size expected by most is probably not too much larger than what is reported, since the presumption is that the effect is mostly implicit bias from many reviewers or explicit bias from a small cohort. In that case, adhering to a strict \(p\) cutoff is electing to have your conclusions from this test determined almost entirely by an explicitly random mechanism. This is surely fool-hardy!
It would seem to me that the more reasonable conclusion is that there is moderately strong evidence of a gender bias in the 2019 CoSyNe review process, but that the number of submissions is insufficient to make a definitive determination possible based off of a single year’s data. This data is unfortunately not available for previous years.
Coda
At the end of the conference, the Executive Committee announced that they had heard the complaints of conference-goers around this bit of gender bias and others and would be taking concrete steps to address them. First, they would be adding chairs for Diversity and Inclusion to the committee. Second, they would move to a system of double-blind review, in which the authors of submissions are also anonymous to the reviewers. Given the absence of any evidence that such a system is biased against men and the evidence that such a system reduces biases in general, this is an unambiguously good move, regardless of the precise \(p\) value of the data for gender bias this year.