At the Intersection of LLMs and Kernels - Research Roundup

Relational databases like postgreSQL and operating system kernels like Linux are foundational building blocks for computing systems. Every “application” is in essence an “application” of those building blocks to some purpose: Twitter applies databases to write and read tweets; it applies an operating system to operate the hardware required to do so.
Large language models – and large generative models of complex data types more broadly – are a new building block at this foundational layer. ML researchers like me have many useful intuitions about what can be built with this novel building block and how to improve it.
But the people who have spent years building with those other blocks have many more. Many of these inuitions are surprising to someone who has spent more time with neural networks than with the network stack.
This post is a collection of short explainers for papers that directly draw from systems metaphors in designing improvements for LLMs, ranging from novel approaches to pretraining to inference-time speed optimizations.
Perhaps most interesting are prompting strategies that make LLMs act more like kernels.
It is intended to get researchers and hackers of LLMs interested in systems and vice versa.
We’ll proceed by first introducing an idea from the systems level – roughly, the interface of hardware, kernel, and application – and then showing how it has been applied to LLMs in recent research.
Update 2023-12-30: the topics discussed here are also covered in this recorded talk from the Scale By The Bay 2023 conference.
Speculative Execution
Speculative Execution in Processors
Sometimes bottlenecks are mitigated by executing the work that most likely follows them: we “speculatively execute” work that will probably, but not necessarily, come after our bottleneck.
For example, rather than waiting for the result of a conditional to be available in order to determine which branch to execute, the processor could simply proceed with the “most likely” branch, based on compile-time hints or runtime statistics. This particular technique for speculative execution is called “branch prediction”.
This can lead to large speedups when a particular branch of a conditional is taken only rarely (e.g. unhappy/error-handling paths) and requires a lot of work to execute (e.g. is subject to cache misses).
Speculative execution is infamous thanks to the Spectre vulnerability, which manipulates runtime statistics to “trick” the processor into executing out-of-bounds memory reads.
Undaunted by that cautionary tale of a multi-billion-dollar vulnerability, let’s consider how we might replicate this pattern of executing cheap but possibly wrong operations to speed up LLM inference.
Speculative Execution in LLMs: Accelerating Large Language Model Decoding with Speculative Sampling and Fast Inference from Transformers via Speculative Decoding
Two roughly-simultaneous papers from Google Research and DeepMind, perennial frenemies, demonstrated roughly-identical methods for large speedups in LLM generation by using cheaper models to predict certain tokens without changing the system’s output probabilities. In essence, speculatively generating a number of likely output tokens before the actual LLM is used to compute the final outputs.
The intuition behind speculative sampling is that some of the tokens in the output are very easy to guess – a period will come at the end of this sentence, for example – and so can be predicted very cheaply.
These methods further take advantage of the fact that computing the logprobs for a prompt + K tokens can be done in parallel. That makes it much cheaper than sampling K tokens to follow a prompt, which must be done serially – a painful and unavoidable fact of autoregressive models like Transformers or RNNs.
The K tokens following the prompt are generated by some cheap strategy – a smaller language model or even a heuristic rule. We then compute the logprobs for the prompt + K tokens in the large model, in parallel, and then throw out only those tokens that are improbable according to the large model.
Importantly, we reject samples in direct proportion to how improbable the large model thinks they are, so the combined system has the exact same output behavior as the original large model, but generally runs faster. This is a classic trick, rejection sampling, that goes back to the very first (analog!) computers in the 1940s.
For temperature 0, aka deterministic sampling, this equates to throwing out all tokens that follow the first wrong token put out by the speculative process.
The basic flow is captured well in this animation of speculative sampling from an excellent explainer by Joao Gante of Hugging Face:
As with branch prediction, we do some work that might be wasted: running the draft/speculative model and scoring logprobs on all K tokens.
But because running the model on the prompt + K tokens is roughly the same cost as executing on the prompt + 1 token, for small K, we almost always come out ahead – much as branch predicting speculative execution comes out ahead because reading from memory and then executing the right branch is roughly the same cost as executing a wrong branch while reading from memory and then executing the right branch.
When used in a hierarchical configuration – regexes speculating for BERTs that speculate for GPTs – speculative sampling can achieve 2x speedups or greater.
Note that 2-3x is the typical cost difference between prompt tokens and output tokens in LLM APIs, and so well-executed speculative decoding can reduce that cost difference to almost nothing (thanks to Moin Nadeem of Replicate for thoughtful discussions on this).
Registers
Registers in Processors
Programs generally achieve their effects on the world by writing information to memory visible to other processes or hardware – RAM or disk for other processes, VRAM for the display, network sockets for other computers, etc. Registers store small amounts of intermediate data during the computation of this information.
Unlike stack-allocated or heap-allocated memory, these values are stored in the processor itself and are essentially inaccessible to the programmer (without assembly-level backdoors) in high-level languages like C.
Because they are abstracted away from the programmer, they can be manipulated – e.g. by a compiler when optimizing the program – without concern for the side effects of those manipulations.
How might this pattern show up in LLMs?
Registers in Large Transformer Models: Vision Transformers Need Registers
Alright, this is cheating a bit, because it’s Vision Transformers, rather than Transformer language models, but it’s still a cool paper so I’m going to explain it.
There’s also a weaker but similar result for LLMs, based on “pause tokens”.
This paper claims that
- Vision Transformers use uninformative pixels as dynamic registers for storing intermediate information
- You can intentionally add empty “register tokens” to the input to remove this behavior
The first point is backed up by this gorgeous figure:
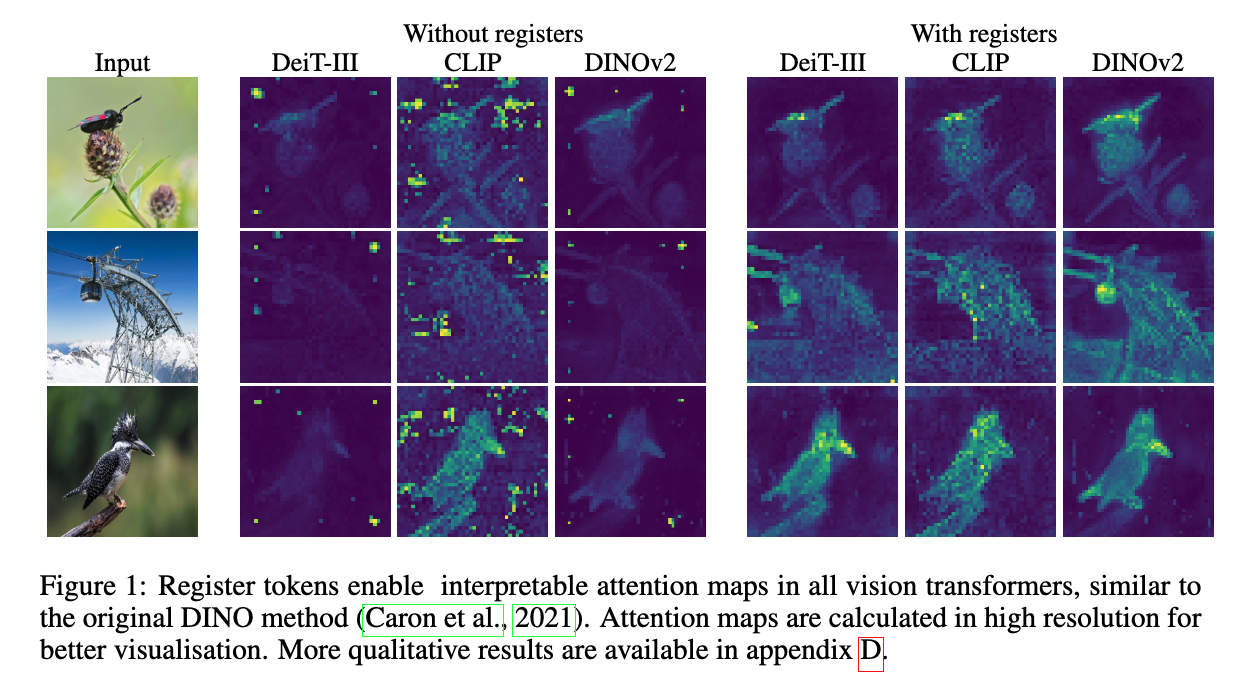
The bright colors indicate areas of the image to which the models attended when producing their predictions. Notably, large ViTs attend heavily to uninformative, background pixels.
Does this mean the models are learning to use artifacts of the dataset or adversarially-attackable side channel information to make their predictions?
Not necessarily!
Because each layer interacts additively
with its inputs –
the output of a layer with input x can be written as f(x) + x –
Transformer layers can treat their inputs
like a content-addressable memory,
reading information written by earlier layers and writing in some of their own.
For more on this view of Transformer internals, see the excellent
work from Anthropic’s interpretability team.
It’s a neat way to do computation, but it has a big issue: if you want to write information that’s not tied to a specific token position, you don’t have a good place to put it.
It is hypothesized in the paper that large ViTs learn to use the least-informative token areas as a kind of scratchpad – like stealing a block of memory, using it to store intermediate values, and hoping you don’t break anything.
The paper proposes adding some blank “register” tokens to the input in order to give the model a safe spot to store the results of calculations that don’t otherwise have a place to go.
The addition of registers does not meaningfully improve performance on benchmarks (cf. Table 2 in the paper), but the resulting attention maps are much cleaner, as is obvious from the figure above, and so one might expect some downstream benefits, e.g. to interpretability or steerability.
Paged Memory
Paged Memory in Processors
Memory must be allocated, and those allocations must be tracked and managed, e.g. defragmented, to maximize utilization of memory resources, which were precious even before the Chrome Nation attacked.
Memory allocators must handle a gnar trade-off: address-wise allocations make efficient use of memory in the best case, but lead to fragmentation and expensive allocator operations in reality, while large per-process/thread allocations are easy to manage but lead to wasted memory in the generic case that the allocations are not fully utilized. This particular form of under-utilization is called “internal fragmentation”.
The solution is to split the difference and allocate memory in multiples of moderately-sized blocks called “pages”.
The diagram below, from the BlogOS series by phil-opp, depicts the difference between fixed-size block allocation (left) and paged allocation (right). Notice that the allocation for the process in blue fails in the block allocation case but succeeds with pages.
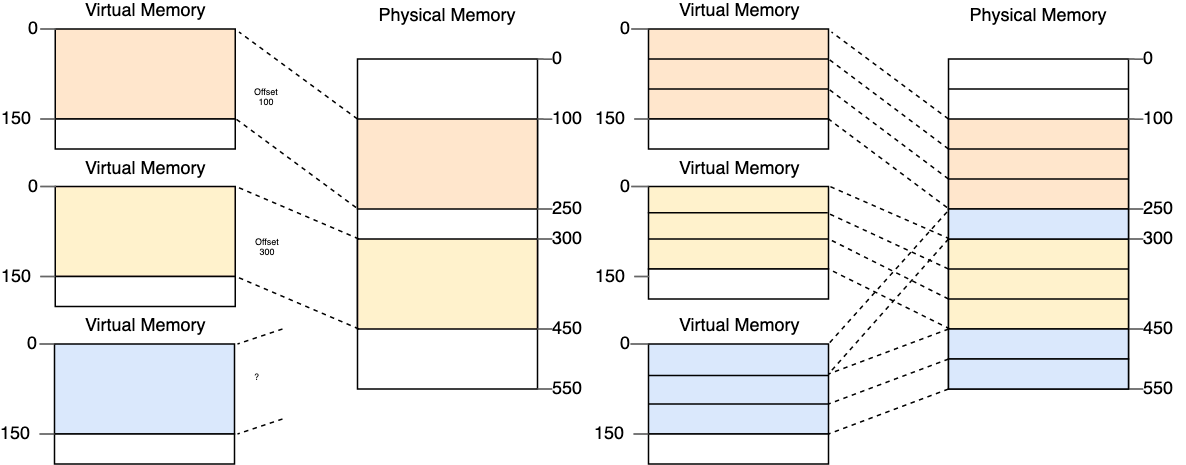
Pages can be assigned to processes, loaded into caches, and otherwise managed as bulk units, while still being small enough (4 KB by default in most Linuxes) to be efficiently utilized.
LLMs are memory intensive, so might we be able to improve their performance by designing a better allocator?
Paged Memory in LLMs: Efficient Memory Management for Large Language Model Serving with PagedAttention
The focus of memory management in LLM inference is on the key-value (“KV”) cache, used to store the intermediate values of attention computations, for re-use when computing the outputs for future tokens in the sequence. This cache, introduced by the 2022 paper Efficiently Scaling Tansformer Inference from Google, converts a quadratic-time operation (compute attention for all token pairs in the sequence) into a linear-time one (compute only attention for the newest token in the sequence), at a linear cost in space (store keys and values for each token in the sequence).
If hot-swappable LoRA adapters ever take off, a similar amount of memory legerdemain will be required for the weights as well.
The KV cache is typically allocated as a single large block of memory, which is subject to the same issues as large block allocations in general.
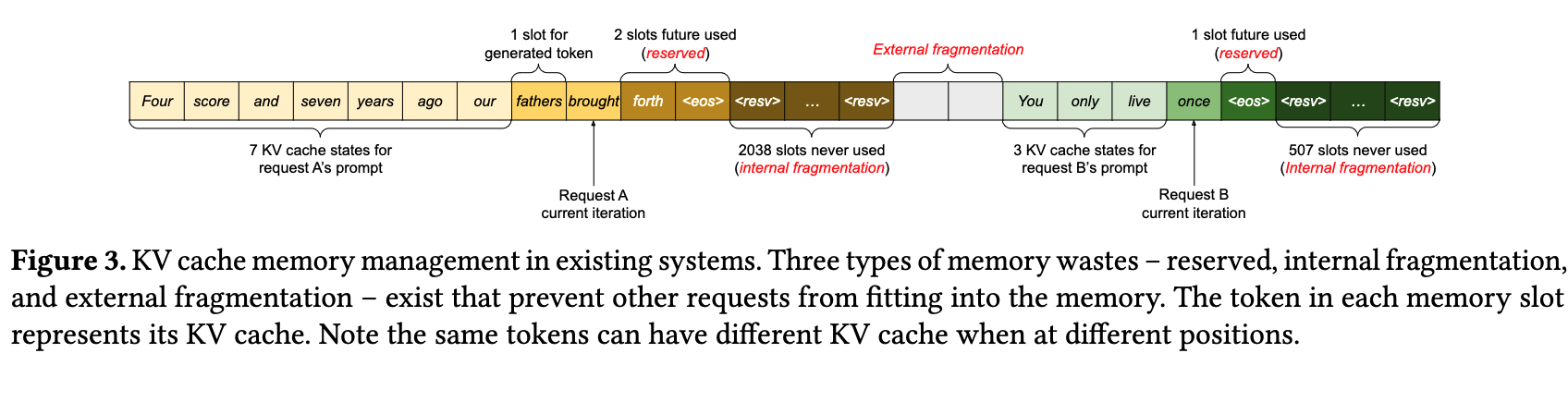
This problem is especially acute for batched requests to LLM services. Because requests from different clients have varying prompt lengths and varying response lengths that are not known until run time, the utilization of the KV cache becomes highly uneven.
The situation is depicted nicely in this figure from the paper that introduced PagedAttention and the vLLM inference server that uses it. Note that the “internal fragmentation” sections should be several hundred times larger than they are depicted here!
The solution proposed by the paper is to allocate the KV cache via pages – each one with enough space to hold a handful of KV states – and use a page table, much like the one in a processor, to map the logical memory of the cache to its physical address.
Like this:
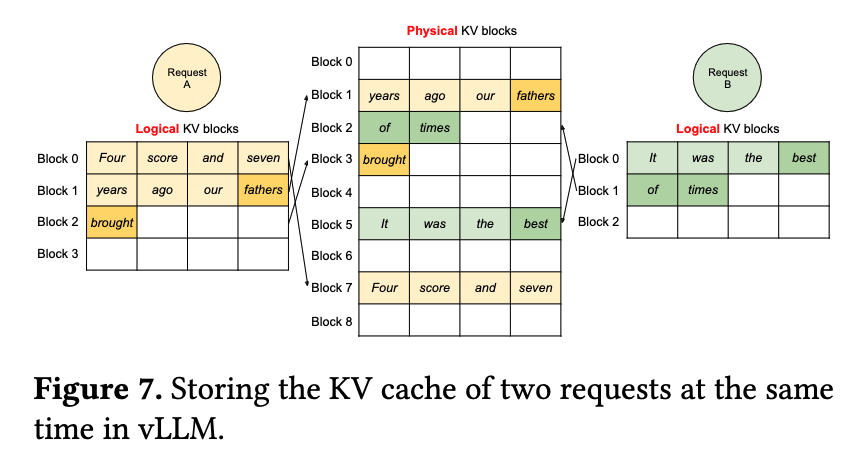
The vLLM inference server that uses this technique is much faster than peer systems and allocates far less memory to serve the same workloads.
Virtual Memory
Virtual Memory in Processors
In the beforetimes,
when metal was metal,
programmers stored information at addresses with names like
0x0BFF
and they really meant it.
They could expect that if they took their trusty oscilloscope to the
3,071st/0x0BFFth
memory cell of their spacious 64KB of RAM,
they would find humming electrons vibing to the pattern they had stored.
This has an obvious problem:
if two 00s tween programmers attempt to use the one and only 0x0BFF address
to store program data at the same time,
someone’s data will be overwritten or read improperly –
akin to the problems of addressing more than one person as your BFF.
Larger address spaces allow for the definition of additional BFFs, e.g.
0x0BFFAEAE
in 32 bit address spaces,
but this only reduces the chance of collision without eliminating it.
The solution is to use a virtual memory system:
programmers and their programs are presented with a gorgeous row
of linear addresses,
from 0x00000000 to 0xFFFFFFFF
(or whatever the highest address is),
and the operating system and hardware map those addresses to physical memory.
This indirection is also useful for pages! Instead of mapping individual addresses, virtual memory maps typically operate at the page level.
Virtual memory’s indirection allows a process to address much more than the available RAM – for example virtual memory addresses can be mapped to locations on disk or on somebody else’s computer.
RAM is limited and expensive, relative to disk, so being able to use disk as memory is a big win.
Language models also have memory limits: when producing tokens, they can only refer to at most a fixed number of previous context tokens.
Hard limits on token count have rapidly increased from the few thousands to the few hundreds of thousands. But models struggle to effectively make use of those long contexts.
How might we apply the pattern of virtual memory to LLMs to also allow them to effectively access much larger storage?
Virtual Memory in LLMs: MemGPT: Towards LLMs as Operating Systems
The MemGPT pattern uses prompting and careful design of tools to give LLMs the ability to manage their context – analogically treating the context as the physical memory and all of the rest of the addressable information as virtual memory.
The pattern is depicted in this figure from the paper:
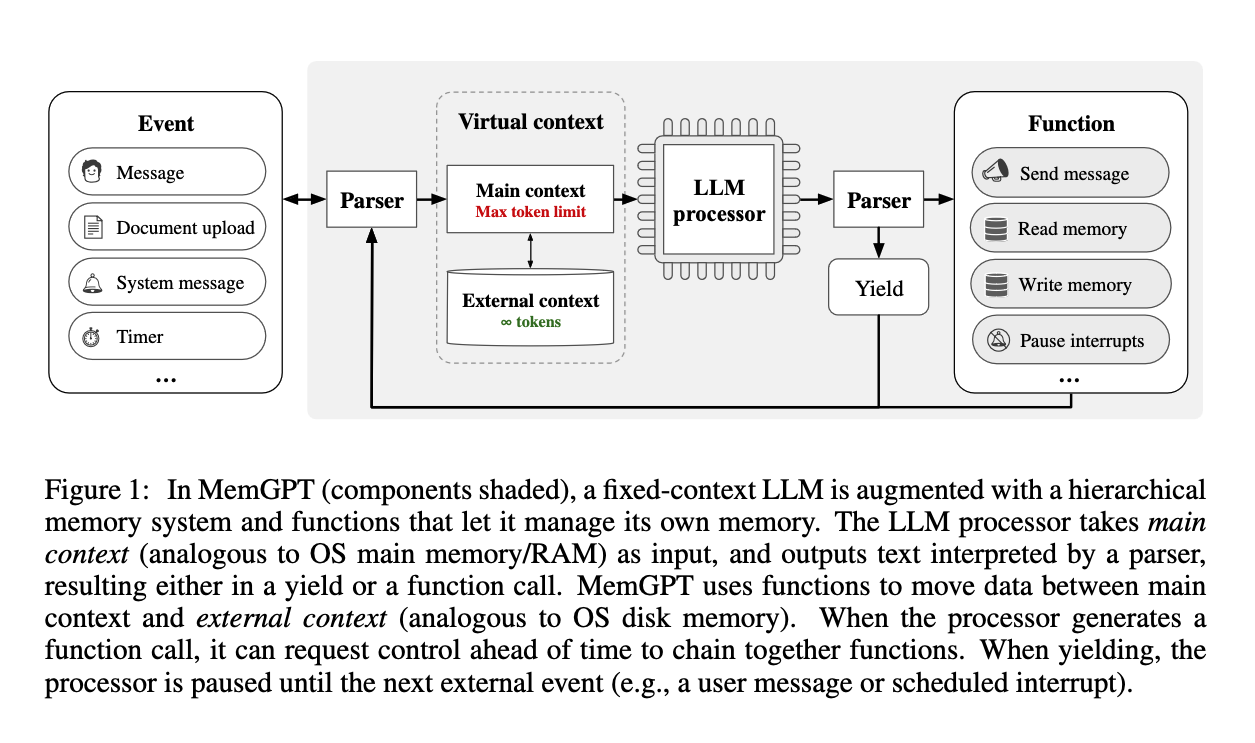
As in retrieval-augmented generation (RAG) patterns, the addressable information is stored outside the LLM and interfaced with by traditional software. That means it can be a database, a filesystem, or any other form of storage.
But unlike typical RAG, in MemGPT retrieval from the external context is done by the LLM, via function-calling tool use, rather than being hard-coded. This style is associated more with agent patterns and is used in the OpenAI Assistants API.
The LLM is prompted to retrieve the information it needs and then add it to its prompt – much like virtual memory stored on disk can be paged into RAM.
Even further down the path to agency and away from simple RAG, in the MemGPT pattern the LLM is also responsible for writing information that overflows the context window back to the storage system. This pattern was popularized by the Generative Agents paper, which uses LLMs to drive video game NPCs. There, agents had the ability to “reflect” on their experiences and write those reflections into their memory.
What Next: LLMs as kernels?
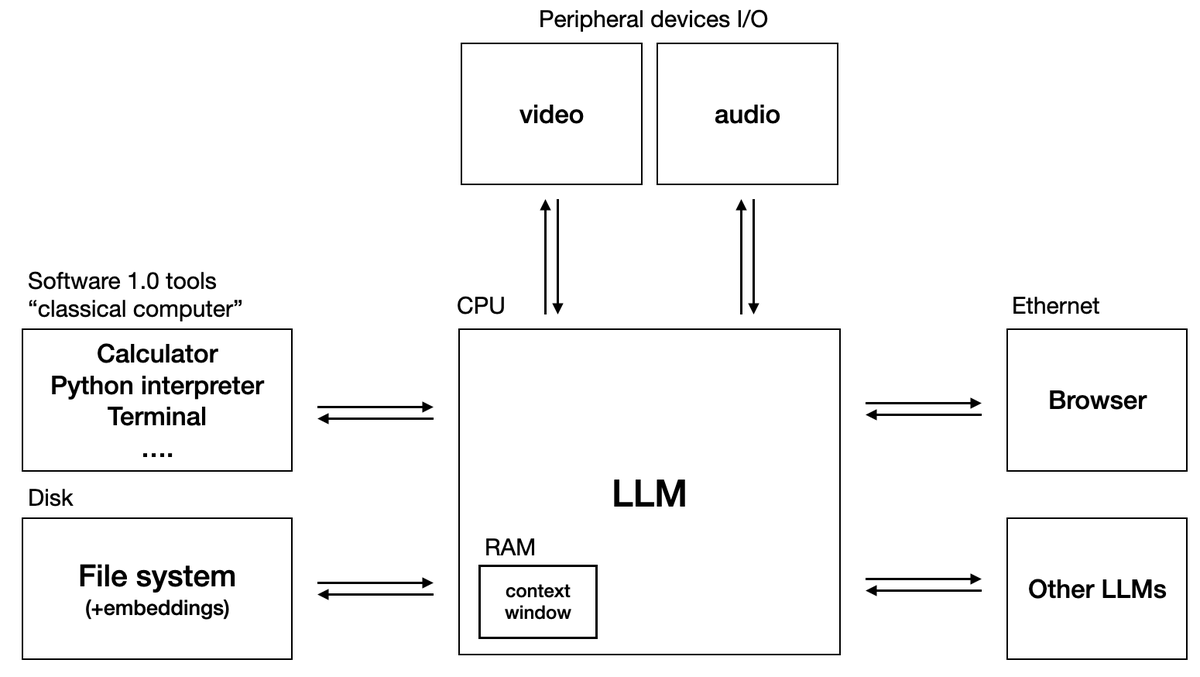 A speculative diagram for an “LLM OS” by @karpathy.
A speculative diagram for an “LLM OS” by @karpathy.
A key novelty of the MemGPT approach, relative to other similar systems, is the event-driven style: the LLM sits idle, waiting for events like user messages, timer ticks, or state changes in the world.
This is an extremely common pattern in the systems discipline – on every keystroke, button press, or filesystem change, a typical operating system interrupts running processes to respond to the event, e.g. to pass the keystroke to the process managing the active window. Browsers are similarly event-driven.
Interruptibility and event-driven-ness are key features of biological agents as well. To quote Copilot’s suggested completion of this paragraph: “If you poke a cat, it will stop what it’s doing and respond to the poke.”
When that suggestion appeared (an event) it stopped me from writing (interrupted my writing process). I was triggered to reflect on it (I handled the interrupt by updating my state). I then went back to writing (resumed my writing process) with a new idea for what to say next.
It is clear that if LLMs are to become the cognitive kernels of agents in any way worthy of the name, they will need a similar architecture.
So while drawing architectures from the computational cognitive science literature is a good idea, we as MLRs should take care to draw from the work on engineering operating systems, browsers, database engines, and other systems as well.
Acknowledgements
I’d like to thank Muhtasham O./@Muhtasham9 for writing a nice blog post that inspired this one, Ben Firshman/@bfirsh for holding a demo space where I could try out the ideas, and Joseph Nelson/@josephofiowa for listening during that first talk and encouraging me to write this post. Joe, now you owe me some VLM benchmarks!
I’d also like to thank Ben Firshman/@bfirsh, Greg Kamradt/@GregKamradt, Jason Liu/@jxnlco, Joseph Nelson/@josephofiowa, Muhtasham O./@Muhtasham9, Ben Shababo, and Alok Singh/@TheRevAlokSingh for reading earlier drafts of this post.